
In clinical IVF, one of the most challenging decisions doctors face is selecting which embryo to transfer first when several look promising in the petri dish. In recent years, artificial intelligence (AI) has emerged as a highly anticipated tool. Currently, mainstream AI models for embryo selection are typically trained to predict the likelihood of live birth for individual embryos. The most common evaluation metric in the field for assessing these models is the Area Under the Curve (AUC).
However, the paper discussed here points out a critical limitation: AUC measures a model’s average discriminative ability across a large set of embryos, whereas in real clinical practice, physicians evaluate a group of embryos from the same patient and must choose the single best one. Therefore, what the clinic truly needs may not be the predicted probability for an individual embryo, but rather the AI’s ability to rank embryos within the same cohort.

Innovation of the Study
This paper first identifies a major flaw in current AI research for embryo assessment: traditional metrics such as AUC primarily reflect a model’s average predictive performance for individual embryos, yet in real clinical scenarios, doctors must choose among multiple embryos from a single patient. Relying solely on AUC thus fails to fully capture the practical value of AI in embryo selection.
Against this background, the study proposes re‑evaluating AI models from the perspective of ranking performance and introduces the metric of severe misranking rate to measure how often a model produces clearly unreasonable rankings.
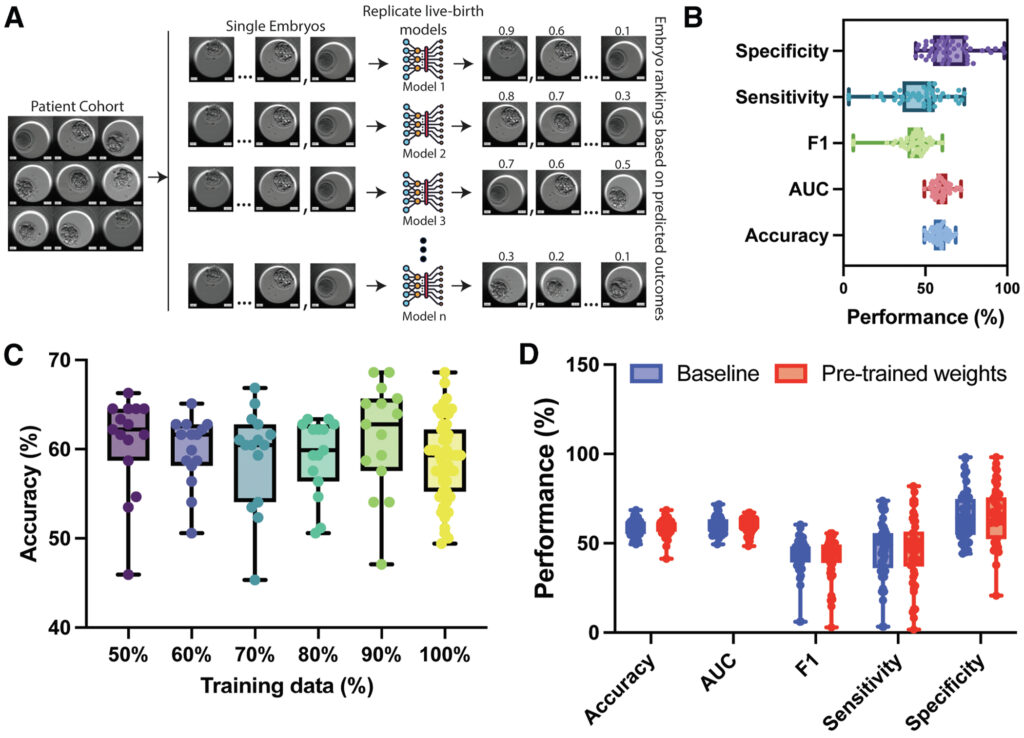
Furthermore, the research trained 50 models with identical architecture but different random initializations, systematically comparing their ranking outputs to better simulate real‑world clinical decision‑making. This provides a new framework for evaluating AI performance in embryo selection.
Key Findings
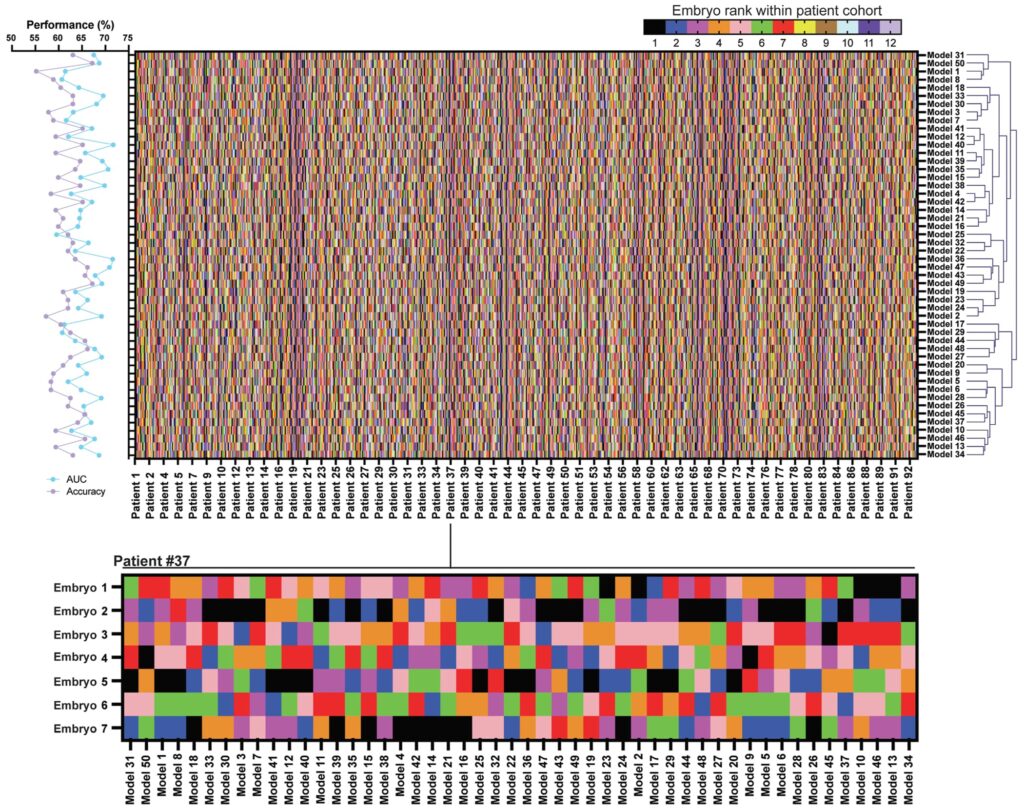
Based on traditional metrics, the AI models appeared to perform reasonably well, with an average predictive performance of approximately 0.60. However, when the researchers compared embryo rankings generated by different models, they found low consistency: the rank correlation coefficient among the 50 models was only around 0.35. This indicates that even with nearly identical AUC values, different models may disagree sharply on which embryo is best.
A particularly concerning observation was that in roughly 15% of cases, some models ranked embryos with clearly lower developmental potential first—even when higher‑quality blastocysts were available within the same cohort. Such errors can be masked in overall summary statistics but may directly impact transfer decisions in clinical practice.
Interpretability analyses also revealed that different models focused on distinct morphological regions of the embryo in images, suggesting that AI systems may rely on different decision cues and thus reach completely different judgments.
Clinical Implications
A key takeaway from this study is that ranking ability is far more important than standalone predictive power in AI evaluation frameworks for IVF.
In routine IVF practice, physicians are rarely tasked with judging whether “an embryo has potential”; instead, they must rank and select among multiple embryos from the same patient. Even if an AI achieves favorable predictive metrics, it may not provide stable or reliable ranking advice in multi‑embryo selection scenarios.
Consequently, future development of IVF‑focused AI models should better align training objectives with real clinical tasks. For instance, model evaluation should incorporate clinically relevant metrics such as embryo ranking consistency and top‑quality embryo selection accuracy, rather than depending exclusively on traditional predictive measures like AUC. Only when AI can stably perform the core task of embryo ranking can it become a truly effective aid for clinical decision‑making.
Limitations
This study focused on analyzing the consistency of model rankings and did not systematically compare different model architectures or training strategies. The findings therefore highlight potential limitations of current evaluation methods, rather than providing a comprehensive conclusion on all AI approaches.
In addition, the AI models trained in this study did not represent state‑of‑the‑art performance in the field, and commercially or clinically deployed AI systems were not evaluated. As such, the results do not reflect the best‑in‑class performance of AI in IVF.
Conclusion
As artificial intelligence rapidly integrates into medicine, high statistical performance metrics often fuel optimistic expectations. Yet this study serves as an important reminder: strong statistical scores do not always align with the real needs of clinical decision‑making.
In IVF care, clinicians do not face the question of “whether one embryo is viable”—they must choose among multiple embryos. Predicting the outcome probability of a single embryo is therefore insufficient to solve practical clinical problems.
Moving forward, the evolution of IVF artificial intelligence may shift from a narrow focus on predictive performance toward clinically meaningful ranking capability. Only when AI can generate logical and stable priority rankings within a cohort of embryos will it become a reliable and trustworthy assistant for reproductive medicine specialists.